![]()
 |
Ph. D., ass. prof.,
Experience in EVP and ITC:
7 years (from 2002)
Education:
graduate
(2001), Ph.D.(2008). Author of studies in the field of mechanics,
experimental parapsychology, founder of the first Russian scientific
|
|||||||||||||||||||||
|
Artem V. Miheev, Ph.D., ass. prof,
Vadim K. Svitnev, Ph.D.,
hydroacoustician
Computer speech phenomena:
Introduction. The study of electronic voice phenomenon (EVP), opened in 20th century by Friedrich Jurgenson, has its history at least 50 years. In general, existing methods of EVP recordings can be divided into 3 classes: microphone technique (Jurgenson), radio methods (Jurgenson, Raudive, Franz Seidl, Marcello Bacci, etc.) and recording by use of special devices (George Meek, Hans Otto Koenig , Jules and Maggie Harsh-Fischbach, etc.).
Preparation.
First, you need to create a sampler in the form of "canned" speech
from the mixture in a foreign language. Any recording with a mixture
of four or five foreign radio stations, carefully checked for possible
coincidences with the native speech can be suitable.
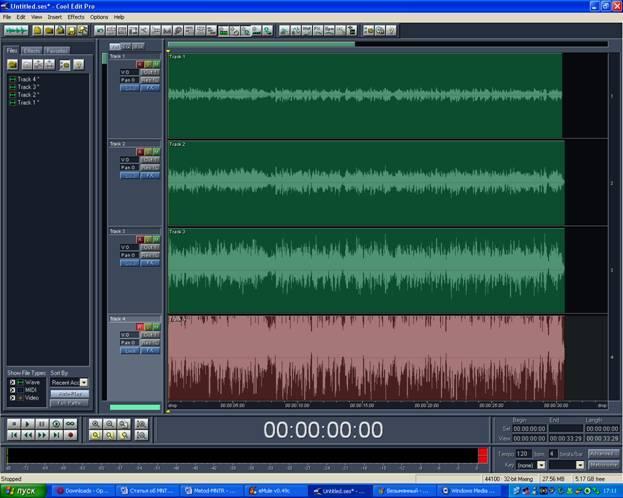
Procedure of recording. Using the standard program Windows Media Player, mp3-file with "cans" is run for playing. It’s necessary to adjust the volume of Windows Media Player (in our experiments it was the level of 15-20 percent). You should also adjust the volume of internal sound card mixer.
This procedure must be repeated 4 times. After
four-stage overlaying of
the re-recorded speech signal amplitude
becomes maximal. The result should look something like this:
Note 1.
If you want to choose the number of tracks, other than four, you must
select a different initial volume of "cans"
Note 2.
Despite of the author’s commitment to elementary style of
presentation, it is not an exhaustive guide to the use of software
Cool Edit Pro and Adobe Audition. For complete information we strongly
recommend you to consult Help menu or the relevant literature.
Note 3.
We strongly recommend you to disable your speakers (headphones) till
the end of recording.
Listening and Processing. Since on the fourth track your question via the microphone is not always heard clearly, we recommend you first call the first track (by the double clicking on it by the left mouse button), listen to your question and remember the time where it ends on the timeline. Your answer (EVP) is located on the fourth track.
The
1st variant of processing.
The
2nd variant of processing.
Note 4.
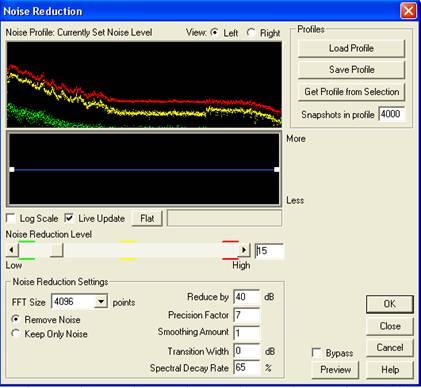
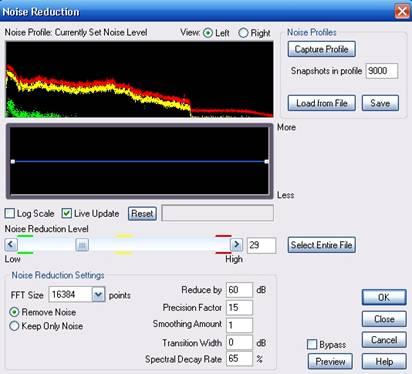
Before processing of
the
tracks by Noise Reduction, you can cut off all the frequencies above 4
kHz using the FFT filter, or a graphic equalizer (menu «Filters»)
Possible explanations.
The most "naive" explanation of experimentally proved working of this
method is that the man’s subconsciousness "catches" some fragments of
speech, and gives them a meaningful interpretation.
1.
The real answer (which often represents a single word or sentence that
gives an answer or a comment to experimenter’s question) stands out
very clearly against the overall speech signal, can be filtered and
consistently identified by experimenters.
2.
There is a dependence of the number of responses received on the state
and mood of the operator: in certain conditions (inappropriate time,
operator’s fatigue) there are no responds at all, and it is confirmed
by bystanders.
3.
Finally, in violation of certain conditions, the effect is modest or
disappears altogether.
So,
let us consider other explanations:
1.
Influence on the microphone signal by entities from the “other side”,
which is chosen in such a way as to enhance or suppress individual
phonemes during recording "stochastic" phonemic material.
2.
Similar effect on the sound card.
3.
Manipulation of error in the sampling (digitization) of the analog
signal on the sound card, the accumulation of errors during successive
re-recordings through the internal sound card mixer.
4.
Influence on the PC processor during signal processing (it is the last
stage - application of the function Noise Reduction).
We
draw a parallel here with the video-method of Klaus Schreiber, who
sought the full manifestation of his paranormal images through
successive iterations – i.e. series of re-dubbing a picture from the
screen on the film (see [1])
Comparison with the Stefan Bion’s program EVP Maker ([2]).
Similar to the program
EVP Maker, quasi-random verbal factor
is used
as the raw material for the formation of
the responses, but the difference is that the formation of the signal
is not discrete, but continuous, and moreover, in our method emergence
of quite distinguishable separate EVPs takes place. These EVPs are
quite characteristic and suitable for filtering.
Advantages of the method.
1.
2.
Exclusion of the argument of “random radio broadcasts” (signal is not
broadcasted through the air, it’s never going beyond the sound card)
3.
High frequency and quality of the responses.
4.
Widespread availability of the method and its performance (distinct
meaningful answers come in almost every session).
The
disadvantages of the method are:
3.
Difficulty of the method for experimenters who are not familiar with
the applicable software.
Additional factors.
It
was discovered during experiments, that additional factors, such as
quartz crystals, ultraviolet lights, metronome, rhythmically flashing
fluorescent lamp, have a positive impact on the process of EVP
recording, but they are not necessary.
Instead of re-recording through the internal
mixer, you can use a combination of
FM
- transceiver which broadcasts "canned" speech to the radio (tuned to
unoccupied FM radio frequency, connected to the sound card through mic
input.
Parallels.
The phenomenon of EVP in a computer without any external microphone
signal was also opened by Brazilian researcher Sonia Rinaldi ([3])
References.
1.
Hildegard Schaefer. Bridge between the Terrestrial and Beyond.
http://www.worlditc.org/c_04_s_bridge_content.htm 2. http://stefanbion.de/evpmaker/index.htm
3.
IPATI Bulletin № 23.
For more
information go to the
presentation of
some of our projects (part of them have been
successful):
http://www.rait.airclima.ru/ITC_Project.doc |
||||||||||||||||||||||
|
You are visiting our website:
W |